
0%
接下來要來帶大家認識
在前幾篇文章中理解分類問題及整合學習方法後,我們必須深入研究如何調整模型的參數以獲得更好的性能,接續閱讀瞭解更多內容吧~
在電腦科學的領域中,有一個特殊的習慣:特定的術語有時可以互換使用。例如,在程式設計領域中,儘管 Parameters 和 Arguments 從嚴格的定義上有著不同的涵義,但它們經常被視為同義詞。在函數方法的定義中,Parameters 是一種暫存變數 (Placeholders),用於接收傳入值;而 Arguments 是指在程式執行函數呼叫時,實際傳給函數方法的值。同樣地,在機器學習領域中,當討論 Parameter 與 Hyperparameter 這兩個術語時,也會發生類似的情況。
在實作人工智慧(AI)解決方案時,資料科學家面臨的一個艱難的挑戰便是模型的優化和調整。這也是機器學習(ML)和深度學習(DL)理論中,眾多分支所探討的重要課題之一。通常,模型優化 (Model Optimization) 是指定期進行調整以最小化輸出誤差或提高模型準確性的過程。然而,在實際建模的過程中,ML 和 DL 模型的優化往往卻是需要對模型的內部和外部元素進行微調,確保模型可以滿足預期的準確度。
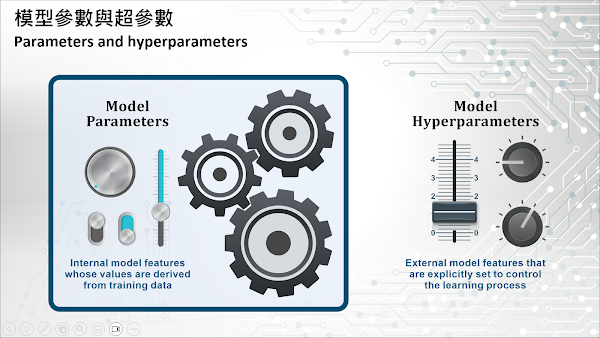
模型參數 (Model Parameter) 是模型內部的配置變數 (Configuration Variable),也是模型的重要組成部分。這些參數是透過訓練資料集進行學習而產生,並非由資料科學家手動設定而來。也就是說,它們是使用優化演算法估計而得出的結果,這是一種透過可能的參數值進行的有效搜索的過程。因此,在實際進行預測時,參數會被視為模型的一部分,是模型必要的重要元素。以下是一些模型參數的例子:
在建立人工智慧(AI)解決方案時,模型超參數 (Model Hyperparameter) 是一個重要的概念。超參數是模型外部的配置元素 (Configuration Element),儘管它不屬於模型的一部分,但卻會嚴重影響模型的行為。與模型參數不同,超參數值通常無法從訓練資料集中估計得出,需要資料科學家手動指定(雖然資料科學家常用啟發式方法來決定超參數值),並且經常會針對特定的預測建模問題進行調整。模型超參數有助於控制模型的學習過程,雖然它們最終不會出現在模型實際的預測中,但卻對理解學習階段完成後的參數有很大的影響。以下是一些模型超參數的例子:
參考資料:無
