
0%
透過前幾篇介紹的機器學習內容,相信大家已經有初步的認識,接下來將詳細的介紹機器(深度)學習的工作流程
通常,企業建立、訓練、部署和使用機器學習(ML)和深度學習(DL)模型需要遵循下圖中描述的七個步驟。這七個步驟可以被區分為資料準備 (DATA) 和模型建構 (COMPUTE) 這兩個階段,接下來我們會將這七個步驟濃縮為五個步驟,並分別說明其內容。
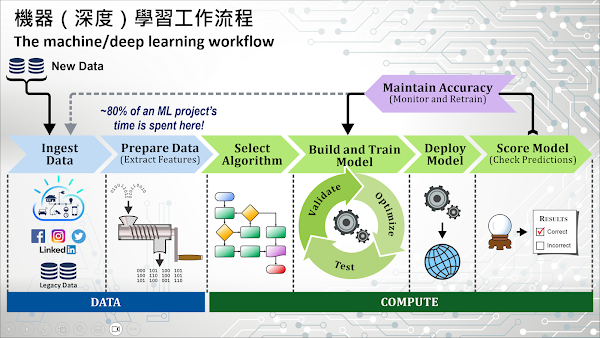
資料取得是建立 ML 和 DL 模型的第一步,包括擷取、轉換和載入三個主要步驟。資料擷取通常是指從各種應用系統中獲取資料;資料轉換則是清理和規格化資料的過程;最後,將資料載入到(儲存)一個集中位置,通常是易於存取的關聯式資料庫中。根據實務經驗,資料擷取與載入相對容易,但轉換步驟往往具有挑戰性,因為資料可能來自於任何地方並以各種不同格式儲存,例如網路日誌、應用程式日誌、社群媒體網站、影像串流等。因此,在開始建立 ML 和 DL 模型之前,必須將來自不同來源系統的資料轉換為適當的格式。
資料可以透過三種方式取得:批次處理 (Batch)、即時處理 (Real-time)、以及串流處理 (Streaming)。批次處理是處理大量資料的有效方法,這些資料通常是在一段時間,由一組相當大量的交易所產生;即時處理則表示資料必須不斷地從來源系統中同步儲存到目的端資料庫系統中;串流處理一般是指由 IoT 等物聯網設備所產生的文字或影像資料,這類型的資料可以使用 Apache Spark 或 Kafka 等平台進行立即性處理,通常用於預測性分析 (Predictive Analytics) 等情境。
要解決預測性分析問題,通常可以嘗試多種統計演算法。在確定最佳演算法之前,資料科學家必須進行大量的實驗和錯誤測試,因此這個步驟通常需要花費一些時間。
在這個階段,需要進行密集的計算工作,通常需要具備大量的資料科學專業知識。這些工作包括開發初始模型、設置模型的超參數 (Hyperparameters) 和調整模型參數,讓模型可以達到最高水準的預測精準度。這個過程同時融合了藝術與科學,企業對於資料科學、ML 和 DL 專業知識技能方面的成熟度,往往直接影響了 ML 和 DL建 模專案的成功與否。
機器學習模型最初是透過歷史資料進行訓練,然後藉由輸入即時資料推論其預測結果(評分)。為了實現即時評分,訓練好的模型需要部署在接近應用系統的位置。有時可以將模型部署為可獨立運作的微服務,但更多的時候是將其打包裝為程式組件,作為應用系統程式功能的一部分。在這個階段,企業可以利用 ML 建立輔助業務決策的流程,或透過更精確的資料推論提升企業競爭優勢。
在模型部署並使用後,持續監控模型是至關重要的,有時候甚至還需要重新建立或重新訓練模型,以確保其預測品質不會隨時間而降低。因此,這是整個機器學習建模流程,最後一個重要的關鍵步驟。藉由持續監控和優化模型,確保在生產系統中實際運行並使用的模型在其生命週期過程中,始終維持高水準的預測準確性。
