
0%
隨著我們更深入瞭解AI,或許會遇到一些更具挑戰性的問題,這次我們將更深入探討低度擬合與過度擬合的原因,以及更多相關內容,一起看下去吧~
可以這麼說,機器學習(ML)模型的唯一目標就是擁有良好的泛化 (Generalization) 能力,也就是當它們面對從未見過的輸入資料時,能夠提供合理的輸出或精確的預測(我們也可以使用“一般化”這個詞來協助您理解)。泛化指的是透過將共同屬性抽象化,從少數事實中形成一般化概念的能力。例如,如果您知道貓的外觀特徵,應該可以輕易地識別圖片中的貓,而不受顏色、大小或在照片中位置的限制。這是因為人類本身就具備非常優秀的泛化能力(學習、理解與推理)。然而,相較之下,ML 模型很難像人類一樣具備這種能力。儘管一個訓練有素的模型可以識別圖片中的貓,但如果將這張圖片上下或左右翻轉,它可能就無法成功地識別出這是一隻貓。
從機器學習的觀點而言,資料點可以分為兩種基本類型:一種包含我們感興趣的資訊,即所謂的信號 (Signal) 或樣態 (Pattern);另一種則是由隨機誤差 (Random errors) 或噪音 (Noise) 組成的資訊。以房屋價格為例,除了地理位置 (Location) 之外,房價通常由多個因素決定,例如房屋本身的地塊大小 (Lot Size)、房屋面積、臥室數量等。由於這些因素都對信號有所貢獻,因此較大的地塊面積或房屋面積通常會讓房價更高。然而,在同一地區,即使地塊面積、房屋面積和臥室數量相同,房屋的銷售價格仍然可能存在差異,這種差異即為噪音。
為了讓 ML 模型具有更好的泛化能力,它必須能夠區分信號和噪音。然而,建立一個足夠複雜的 ML 模型來捕捉您想要的信號,又不至於從資料中的噪音中學習,這可能是一個挑戰。這就是為什麼許多 ML 模型會成為過度擬合 (Overfitting) 和低度擬合 (Underfitting) 犧牲品的原因。
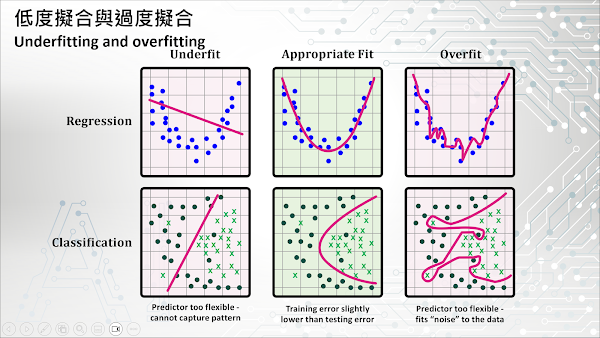
過度擬合 (Overfitting) 指的是一個 ML 模型從訓練資料中學習了過多的細節,導致模型無法辨別真正的信號或主導趨勢 (Dominant trend),而將隨機波動 (Random fluctuations) 誤認為資料的內在屬性 (Intrinsic properties)。因此,這個模型學到的概念對於新的或未見過的資料可能會失效,也就是說這個模型的泛化能力會受到影響。就像一個學生記住了教科書中所有的問題,但在考試中遇到有變化的題目卻無法回答一樣。當模型過度擬合時,在訓練資料上的表現可能非常好,但使用在未知資料時卻可能表現不佳。
當一個 ML 模型過於複雜或過於靈活,就容易出現過度擬合的現象。這種現象可能是因為訓練資料集有太多的輸入變數或模型沒有被適當地正規化 (Regularization)。正規化是一系列廣泛的技術,透過人為強制的方式讓模型變得更精簡,或是讓模型不要太適應訓練資料集,以提升其泛化能力。以下是一些避免過度擬合的方法:
相對於過度擬合,低度擬合 (Underfitting) 是指機器學習模型無法從訓練資料中學習到足夠的知識,以準確地捕捉輸入變數與目標變數之間的潛在關係。低度擬合的模型既不能精確地預測訓練資料集中的預期目標,也無法泛化到新的資料。低度擬合可能發生在使用過於簡單的演算法、缺乏足夠的訓練資料來建立更精確的模型,或者使用線性模型來訓練非線性問題的模型。要解決低度擬合的問題,除了選擇合適的演算法之外,也可以透過增加訓練資料量或減少特徵變數的數量等方式來避免發生這種現象。
參考資料:無
