
0%
在上一篇文章中,我們深入研究了自然語言處理領域,接下來,我們將要共同探討一個引人注目的深度學習技術 —— 生成式對抗網路,若想更理解並利用這一深度學習技術,就趕緊閱讀文章吧!
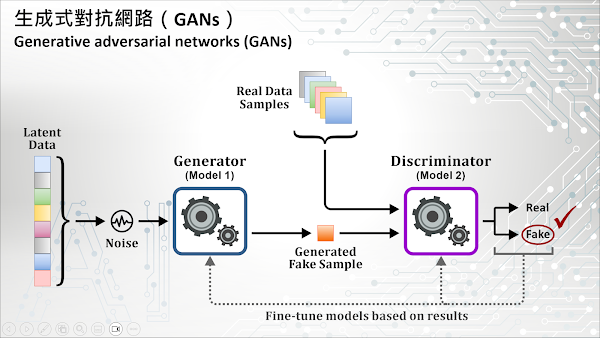
生成式對抗網路 (Generative Adversarial Network, GAN) 是一種深度學習架構,由兩個相互對立的神經網路組成,因此得名“對抗 (Adversarial)”。GAN 目的在更好地分析、捕捉和複製資料集內的變異 (Variations)。它是由 Ian Goodfellow 和加拿大蒙特婁大學 (University of Montreal) 的研究人員在 2014 年提出的論文中提供的方法,這種方法用一種更聰明、更高效的方式來訓練生成式模型 (Generative model)。生成式模型主要是從統計學和機率的角度來解釋資料集被產生的過程。
生成式建模 (Generative modeling) 是非監督式學習中的一個重要領域,它可以自動探索和學習輸入資料中的樣態 (Patterns),並使用訓練好的模型來生成新的範本。例如,我們可以從一個包含大量馬匹圖像的資料集中使用生成式建模的方法來訓練一個生成式模型,這個模型可以產生(生成)一個從未見過的馬匹圖像,而且看起來非常逼真,因為模型已學習到描述馬匹外觀的一般性規則。
資料科學家的研究發現,只要在原始訓練資料中加入少量的雜訊 (Noise),神經網路就很容易被愚弄,因而對事物做出錯誤分類。令人驚訝的是,在加入雜訊後,神經網路模型對錯誤預測的信心甚至比正確預測來得更高。其中一個原因是,大多數機器學習(ML)模型都是從有限的資料量中學習,因此容易出現過度擬合的現象。
為了改善這個問題,GAN 透過將學習任務設定為監督式學習問題並使用兩個子模型來訓練生成式模型:一個是生成網路模型 (Generator model),用於從問題領域中生成出一個新的可信的範本;另一個是判別網路模型 (Discriminator model),用於將前者生成的範本分類為 True(來自真實資料集)或 False(由生成網路模型產生)。換句話說,生成網路模型會試圖愚弄判別網路模型,而判別網路模型則盡其所能避免被愚弄。這兩個模型在一個零和遊戲中一起進行訓練,直到判別網路模型有一半的時間都被愚弄(這意味著生成網路模型產生了相當數量的可信的範本)。
GAN 的訓練是一個相當複雜的過程,其中最大的挑戰就是維持整個系統的穩定性。生成網路模型和判別網路模型之間彼此不斷地相互作用,確保彼此能夠領先對方。然而,它們也相互依賴,以便於進行有效地訓練。如果判別網路模型過於強大,那麼生成網路模型將無法被有效地訓練;反之,如果判別網路模型過於寬鬆,那麼整個 GAN 將毫無用處。因此,保持這種平衡是 GAN 訓練的一個關鍵問題,一般可以透過適當地調整模型架構與超參數,或是採用特定的優化演算法等方法來解決。
GAN 通常被用於產生一些以假亂真的圖片,或是用於產生影片與三維物體模型等。儘管 GAN 最初是透過非監督式學習方式完成訓練,但實證研究顯示,GAN 使用在半監督式學習、監督式學習、甚至是強化學習的領域,也能夠產生不錯的效果。
參考資料:無
